Week 3: Boundary-value analysis, control and data-flow testing
Why Boundary-Value Analysis (BVA)?
Equivalence Partitioning (EP), a technique to divide a program's vast input domain into manageable chunks called Equivalence Classes (ECs). We assume any single test from an EC is as good as any other for finding a bug. 等效分区 (EP),一种将程序的庞大输入域划分为可管理块的技术,称为等价类 (EC)。我们假设来自 EC 的任何单个测试都与任何其他测试一样好,可以发现错误。
However, experience shows that not all inputs are created equal. Bugs, especially "off-by-one" errors, tend to cluster at the edges or boundaries between these equivalence classes. 然而,经验表明,并非所有输入都是一样的。错误,尤其是“off-by-one”错误,往往聚集在这些等价类之间的 边缘 或 边界 处。
BVA is a technique that refines EP by focusing test cases specifically on these boundaries. It's designed to catch two common types of faults that occur at the edges:
- Domain-shift faults: The boundary is in the wrong place (e.g., the code uses
<when it should have used<=).边界位于错误的位置(例如,代码本应使用“<=”而使用“<”)。 - Computational faults: The boundary is correct, but the calculation performed on one side is wrong. 边界是正确的,但在一侧执行的计算是错误的。
Open vs. Closed Boundaries
To apply BVA, you first need to identify the type of boundary you're dealing with:
- Closed Boundary: The boundary point itself is included in the domain. This is created by operators like
=,>=, and<=. - Open Boundary: The boundary point is not included in the domain. This is created by strict inequality operators like
>and<.
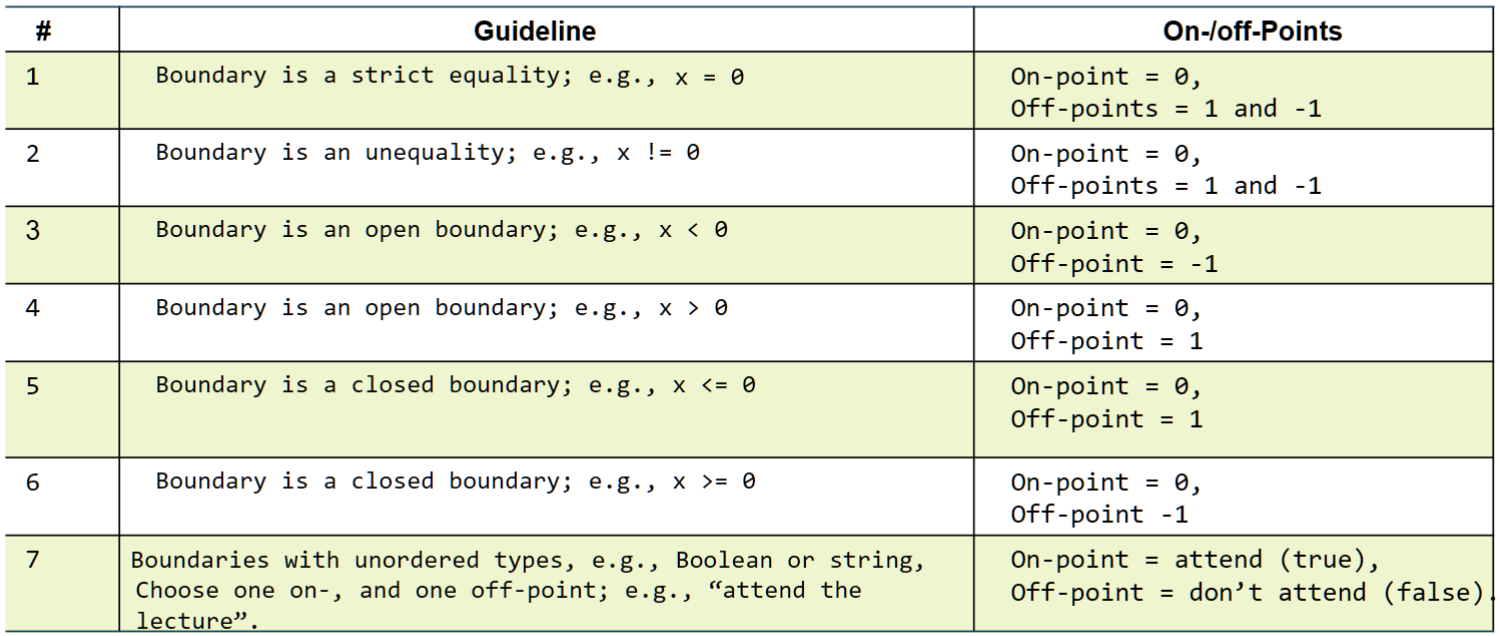
On-Points and Off-Points
Once you've identified a boundary, you select specific test values:
- On-Point: A value that lies exactly on the boundary. This is your most powerful test for finding boundary errors.
- Off-Point: A value immediately adjacent to the boundary, on either side.
For example, for the condition x <= 5:
- The boundary is at
x=5. It's a closed boundary. - The on-point is
5. - The off-points are
4and6.
BVA for Multi-Dimensional Boundaries
Things get more interesting when boundaries depend on multiple variables, like x >= y. This creates a 2D boundary (a line). A simple "boundary shift" could be the line moving, but it could also pivot. 当边界依赖于多个变量(例如“x >= y”)时,事情会变得更加有趣。这将创建 2D 边界(一条线)。一个简单的“边界移动”可能是线移动,但它也可能是枢轴。
A single on-point test like (0,0) might not detect this pivot. To handle this, a rule of thumb has been developed: 像“(0,0)”这样的单个点检验可能无法检测到此枢轴。为了解决这个问题,已经制定了一个经验法则:
- For an n-dimensional boundary, you should select n on-points and 1 off-point. 对于 n 维边界,应选择 n 个点和 1 个离点。
So, for a 2D boundary (x >= y), you would choose:
- Two on-points that are far apart from each other (e.g.,
(0,0)and(10,10)). This "anchors" the line and prevents it from pivoting undetected. 彼此相距较远(例如,'(0,0)' 和 '(10,10)')。这会“锚定”线并防止它在未被发现的情况下旋转。 - One off-point as close as possible to the boundary (e.g.,
(0,1)). 一个尽可能靠近边界的偏点(例如,'(0,1)')。
White-Box Testing & Control-Flow Analysis
So far, we've focused on black-box testing, where test cases are designed based only on the specification, without looking at the source code. 到目前为止,我们专注于黑盒测试,其中测试用例仅基于规范进行设计,而不查看源代码。
Now, we shift to white-box testing, where we use the source code itself to design our tests. The most common form of white-box testing is based on Control-Flow Analysis. 现在,我们转向白盒测试,我们使用源代码本身来设计我们的测试。最常见的白盒测试形式是基于 控制流分析。
Control-Flow Graphs (CFGs)
A Control-Flow Graph (CFG) is a visual representation of a program's logic. 控制流图 (CFG) 是程序逻辑的可视化表示。
- Nodes (Vertices) represent the program's statements.
- Edges represent the flow of control between statements. Edges coming from a decision (like an
ifstatement) are typically labeledTrueorFalse.
CFGs are useful because they provide a language-independent abstraction of the code, helping us make better testing decisions. 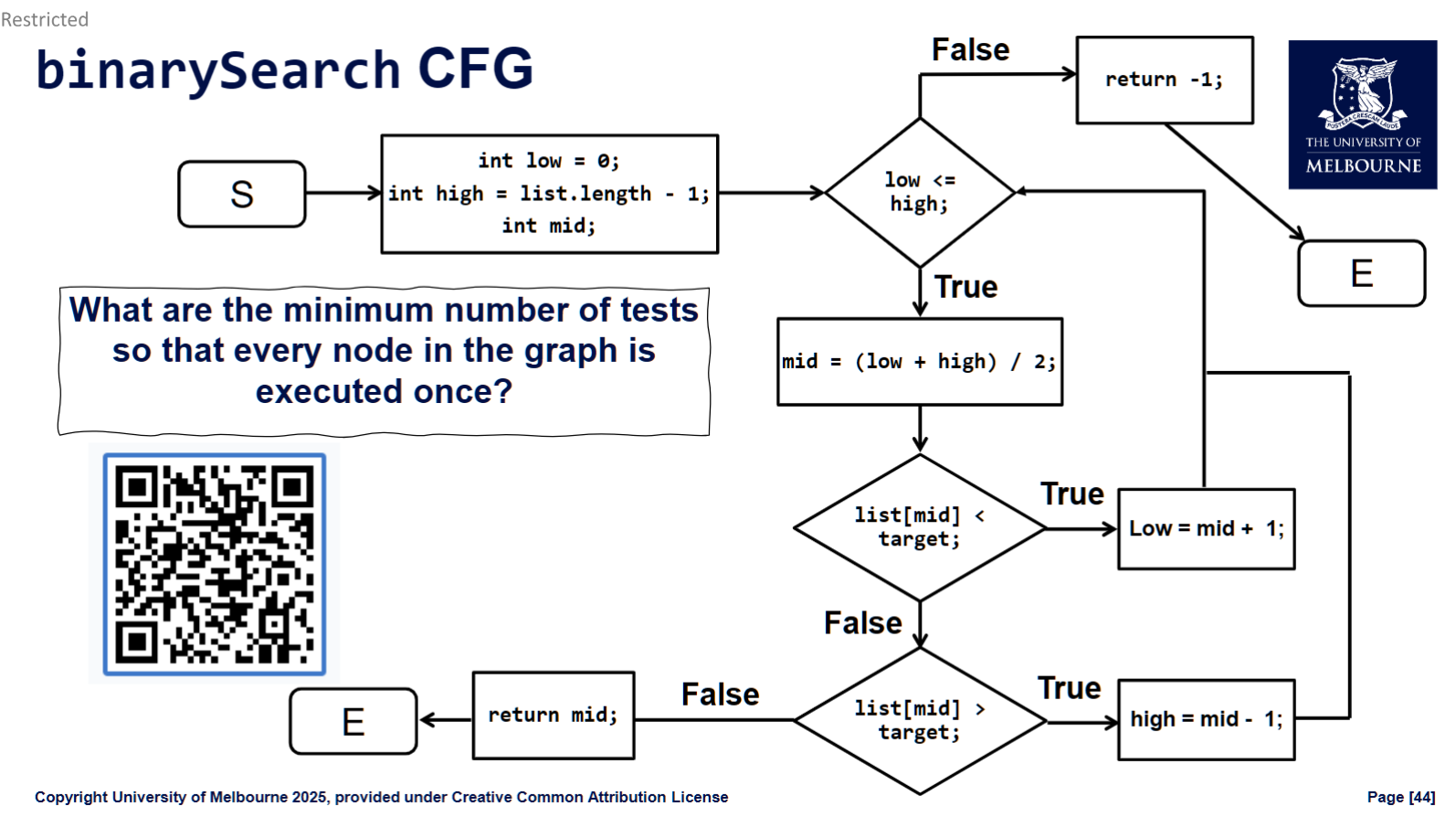
Code Coverage Criteria
Once we have a CFG, we can define "coverage criteria" to measure how thoroughly our tests are exercising the code. The goal is to create a set of test cases that meets a certain level of coverage.一旦我们有了 CFG,我们就可以定义“覆盖率标准”来衡量我们的测试执行代码的彻底程度。目标是创建一组满足一定覆盖率的测试用例。
Here are the key criteria, from weakest to strongest:
Statement (Node) Coverage: Requires that every statement (node) in the program is executed at least once by your test suite.要求程序中的每个语句(节点)至少由测试套件执行一次。
Branch (Decision) Coverage: Requires that every possible branch from each decision point is taken at least once. This means for every
ifstatement, you need a test that makes ittrueand another that makes itfalse.要求每个决策点的每个可能分支至少执行一次。这意味着对于每个“if”语句,您需要一个测试来使其“true”,另一个测试使其“false”。- Branch coverage is stronger than statement coverage. You can execute every statement without necessarily testing every branch (e.g., if there's an
ifstatement with noelseblock). 您可以执行每个语句,而不必测试每个分支(例如,如果有一个没有“else”块的“if”语句)。
- Branch coverage is stronger than statement coverage. You can execute every statement without necessarily testing every branch (e.g., if there's an
Condition Coverage: Requires that each individual boolean sub-condition in a decision is evaluated to be
trueat least once andfalseat least once. Forif (x && y), you'd need tests wherexis true,xis false,yis true, andyis false. 要求决策中的每个单独的布尔子条件至少被评估为“true”一次,至少被评估为“false”一次。对于 'if (x & y)',您需要测试 'x' 为 true,'x' 为 false,'y' 为 true,'y' 为 false。Multiple-Condition Coverage: The strongest criterion. It requires that you test every possible combination of outcomes for the conditions within a decision. For
if (x && y), you would need to test all four combinations: (T,T), (T,F), (F,T), and (F,F). 最强的标准。它要求您测试决策中条件_every可能的结果combination_。对于“if (x & y)”,您需要测试所有四种组合:(T,T)、(T,F)、(F,T) 和 (F,F)。
A coverage score is calculated as a percentage: (Objectives met / Total Objectives). Tools like LCOV can automatically measure this for you and generate reports showing exactly which lines and branches your tests have covered.
覆盖率分数以百分比计算:“(达到的目标/总目标)”。LCOV 等工具可以自动为您测量这一点并生成报告,准确显示您的测试涵盖了哪些行和分支。