Big Data and ElasticSearch
Big Data
Big data challenge
- 数据量 Volume: 通常以Giga/Tera/Peta等单位来计量
- 数据速度Velocity: 随着数据更新的速度加快 新数据备货区并分析的频率提高
- 数据种类 Variety: 数据模式越来越复杂 关系和依赖关系也会更复杂 变化的可能性也会变高
- 数据真实性 Veracity: 数据的来源越多 结构越不规则 真实性也越低
NoSQL 种类
- Key-value store: 功能简单 检索速度快
- BigTable: 每行的列数和结构可以不同 可以灵活自定义拓展
- Document-oriented: 结构化文档存储 xml或json等 存储结构灵活 性能高
Elasticsearch
Quote
一种Document-oriented的数据库系统
节点角色: ES 有两种主要节点角色:主节点 (Master) 和 数据节点 (Data)。 一个节点可以有多个角色。 示例集群有1个主节点、2个符合主节点资格的数据节点和1个纯数据节点。
主节点: 任何时候只能有一个节点是活动的主节点。 其他具有主节点角色的节点是“符合主节点资格的 (master-eligible)”,如果当前主节点发生故障,它们可以接管。 主节点负责集群级别的操作,如创建索引和移动分片。
协调节点: 任何节点都可以作为协调节点,管理查询的执行。
索引、分片和副本:
- 索引(类似于数据库)可以被分割成主分片 (primary shards)。
- 每个主分片可以有一个或多个副本分片 (replica shards)(拷贝)。
- 示例显示了三个具有不同分片和复制配置的索引。
读写操作: 只有主分片可以被更新(写入),更改随后会传播到其副本。 读取请求(查询)可以并行发送到副本分片以提高性能。
容错性: 如果主节点发生故障,会选举一个符合主节点资格的节点来接替它
- Redundancy: 冗余
Cluster Yellow State
黄色状态: 当没有足够可用的节点来妥善分配所有主分片和副本分片时,集群会进入黄色状态。
场景示例: 如果节点3崩溃:
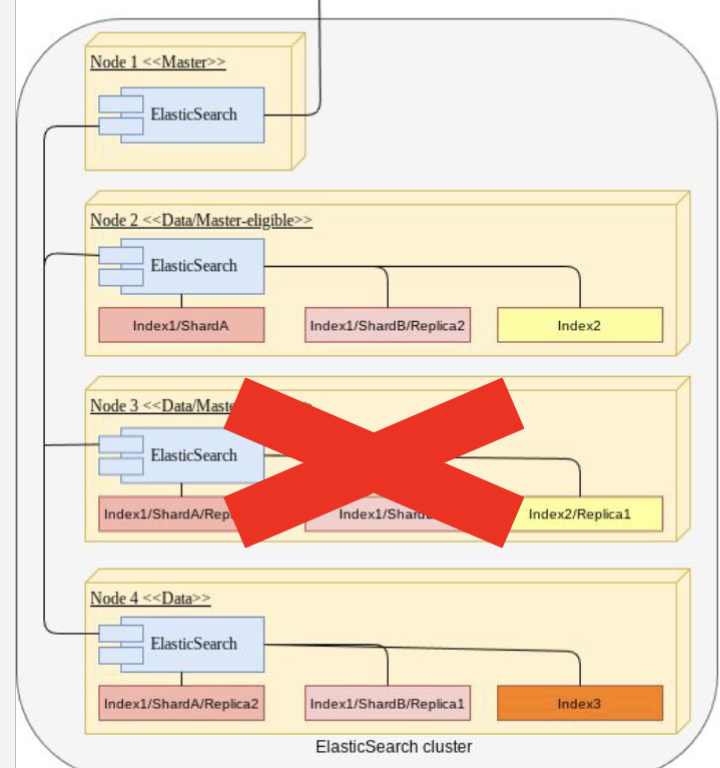
Index1/ShardB 的主分片(位于节点3上)丢失。一个副本(例如,节点4上的 Index1/ShardB/Replica1)将被提升为新的主分片。然而,现在已没有足够的节点来承载 Index1所需的所有副本,因此其状态变为黄色。
Index2 在节点3上的副本丢失。主节点将协调在另一个可用节点(节点4)上重新创建此副本。 一旦重新创建,其状态将变为绿色。
Index3 未受影响,保持绿色,因为它没有副本可以丢失。
在黄色状态下,集群的读写功能仍然完全正常,但数据的冗余级别已受到损害。
CouchDB vs PostgreSQL vs ElasticSearch
ElasticSearch 将对一个索引的写入请求限制在单个节点上(即持有主分片的节点)。 相比之下,CouchDB 允许任何节点接受写入请求。
ElasticSearch 有主节点选举过程。 如果无法达到最少数量的合格主节点(即法定数量 "quorum"),集群可能会停止接受写入以确保一致性。 CouchDB 没有这样的选举;即使其他节点失败,节点也会独立运行。
在联邦式 PostgreSQL 示例中,单个故障节点可能导致整个集群停止工作或使某些数据无法访问。
Consistency, Availability, Partition-Tolerance
- Consistency (一致性): 每个发出请求的client从cluster中的所有节点收到相同的答案。 本质上,所有节点都拥有相同、最新的数据视图。
- Availability (可用性): 每个发出请求的client都能从cluster中的每个节点收到一个答案,尽管这个答案可能不是最新的。 系统总是能响应。
- Partition-tolerance (分区容错性): 即使一个或多个节点与集群的其余部分失去通信(即发生网络分区),集群仍能继续运行。
CAP Theorem
Quote
在一个分布式数据存储中,不可能同时提供以下三个保证中的两个以上:一致性 (Consistency, C)、可用性 (Availability, A) 和分区容错性 (Partition Tolerance, P)
- 一致性与可用性之间的权衡,仅在网络分区实际发生时才变得至关重要。
- 分区并不仅是节点崩溃等罕见的“硬”故障。 “软”分区,即节点仅仅是响应缓慢,更为常见,也可能触发这种权衡,因为系统通常通过超时来检测故障。 例如,ElasticSearch 可能会将来自主节点的 500 毫秒延迟解释为该节点已崩溃,并触发一次选举。
- 现代云环境,拥有大量跨多租户共享的商用服务器,相比传统的、集中部署的高质量服务器集群,会经历更多的硬件故障和延迟问题。
- 因此,CAP 定理迫使现代系统设计者必须有意识地考虑这些权衡

- CA (一致性与可用性):
两阶段提交 (Two-phase commit)算法位于此类别。它优先保持数据的一致性和可用性,但无法容忍网络分区。 - CP (一致性与分区容错性):
Paxos和Raft算法属于此类。它们被设计用来在出现分区时也能保持一致性,但这是以牺牲完全可用性为代价的。 - AP (可用性与分区容错性):
多版本并发控制 (Multi-Version Concurrency Control, MVCC)是此类算法的一个例子。它确保系统在分区期间保持可用,但潜在的代价是暂时的不一致。
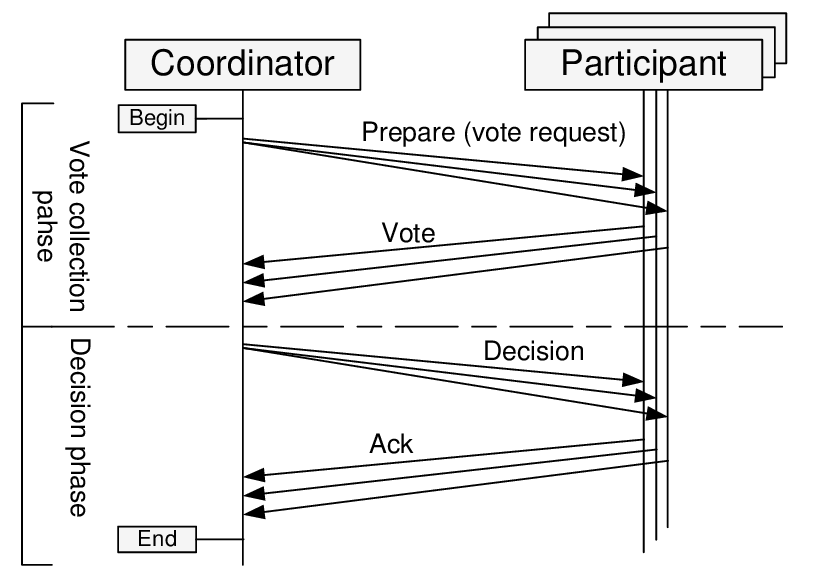
Two-phase commit
Quote
确保多个数据库或资源上的事务被原子性的执行 所有操作要么成功要么失败
- 准备阶段:询问所有参与者是否准备好执行事务
- 提交阶段:仅在集群中所有节点都成功执行事务后,才提交 (commit) 事务。
如果检测到参与者在两个阶段中出现了错误,则中止 (rollback) 事务。 这个过程保证了一致性,但由于数据锁定而降低了性能,并在分区期间牺牲了可用性。 对于集中部署的集群来说,这是一个好的解决方案,但对于分布式集群则不然。
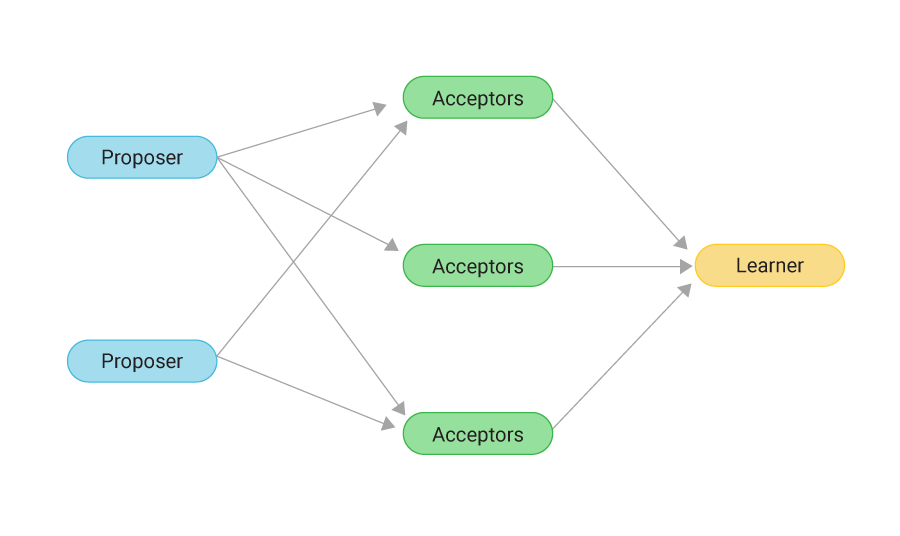
Paxos
Quote
一种分布式一致性算法,也就是共识算法,目标是为了让多个节点就某个值达成一致
角色: 节点要么是提议者 (proposers),要么是接受者 (accepters)。
原理: 主要是通过一个阶段性的投票过程 类似少数服从多数 且即使存在某些节点失败或者出现故障的情况下也能保证正确性
过程:
- 提议者提出一个带有时间戳的值。
- 接受者可以接受或拒绝它(例如,如果它已经收到了一个更新的值)。
- 当提议者收到足够数量的接受(即达到法定数量 "quorum")时,该值即被商定,并发送确认消息。
- 多个Proposer可以同时向多个Acceptor提出提案
权衡: Paxos 集群可以在分区中幸存下来并保持一致性。 然而,分区的较小部分(不在法定数量内的节点)将不会响应客户端,从而降低了可用性。核心思想是利用约束条件(少数服从多数)的来保证分布式系统中的一致性
Leader Election: A single master node is elected by a quorum of master-eligible nodes. This master is responsible for managing the cluster state.
Leader Election(领导者选举): 单个 Master 节点由符合 master 条件的节点的仲裁选出。 该 master 负责管理集群状态。Log Replication: The master node maintains a log of cluster state changes. These changes are replicated to the other master-eligible nodes to ensure consistency.
Log Replication: 主节点维护集群状态更改的日志。 这些更改将复制到其他符合主节点条件的节点,以确保一致性。Quorum-Based Commits: A change to the cluster state is only considered committed and applied after it has been acknowledged by a majority (a quorum) of the master-eligible nodes. This prevents "split-brain" scenarios where different parts of the cluster have conflicting states.
基于仲裁的提交: 对集群状态的更改仅在获得大多数(仲裁)符合主节点条件的节点确认后,才会被视为已提交并应用。 这可以防止群集的不同部分具有冲突状态的“裂脑”情况。Safety and Liveness: The design ensures that an elected master has all the committed changes from previous terms (preventing data loss) and that the cluster can continue to make progress as long as a majority of master-eligible nodes are available.
安全性和活跃性: 该设计确保当选的主节点具有先前时期中提交的所有更改(防止数据丢失),并且只要大多数符合主节点条件的节点可用,集群就可以继续取得进展。
Quote
Minimum number of master nodes = (number of master-eligible nodes / 2) + 1
假设我们有一个 20 nodes的cluster,并且我们分配了 8 个node作为符合 master 条件的节点(节点角色设置为 master)。通过应用此公式,我们的集群将创建一个 quorum,其中包含(精心选择的)5 个符合主节点条件的节点 (8 / 2 + 1 = 5)。我们的想法是,我们至少需要 5 个符合 master 条件的节点来形成 quorum。
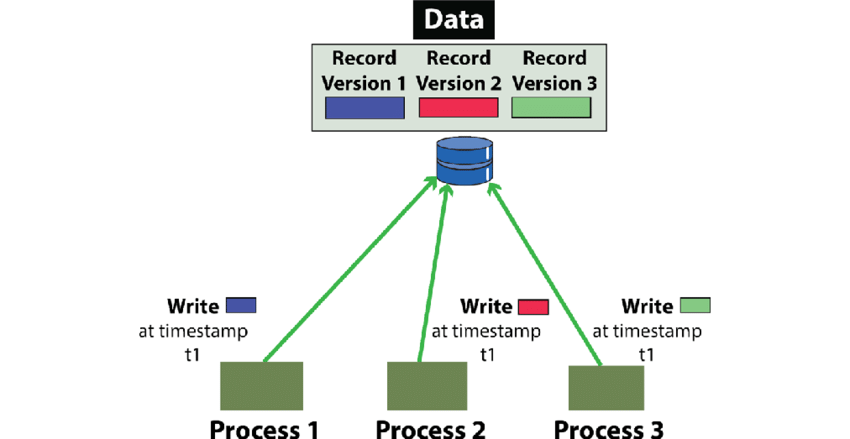
A&P Multi-Version Concurrency Control
Quote
一种数据库管理系统 DBMS的并发控制方法,牺牲了一定的数据一致性,但是确保多个事务可以并发地访问数据库而不会产生冲突
机制: MVCC中 每个对象都有多个版本 伴随着时间戳或序列号
- 当一个事务要读取或写入一个对象时 都会获取对象的一个版本 版本时间戳或需要必须早于事务开始的时间戳
- 对于写操作 事务会创建一个新版本 并写入数据库
- 对于读操作 事务会返回早于其开始时间戳的最新版本
这种方式下多个事务可能会读取数据库的不同版本 但是没有冲突 网络分区的情况下 仍然可以正常工作 但是恢复时会因为数据一致性发生冲突 Git管理代码的方式借鉴了MVCC
冲突解决: 如果发生网络分区,两个节点接受了具有相同修订号的更新,问题就出现了。 当分区解决后,就存在一个冲突。 在像 CouchDB 这样的系统中,数据库不会自动解决冲突;相反,它会向应用程序返回所有冲突版本的列表,然后由应用程序负责合并或选择正确的版本。 这类似于像 Git 这样的版本控制系统处理合并冲突的方式
Recap CouchDB vs PostgreSQL vs ElasticSearch
- CouchDB: 使用 MVCC,使其成为一个 AP(可用性 + 分区容错性)系统。 它即使在分区期间也优先保证可用性,但可能牺牲一致性。
- ElasticSearch: 混合使用了两阶段提交(用于数据复制)和类 Paxos 的选举(用于选择主节点),使其成为一个 CP(一致性 + 分区容错性)系统。 它在分区期间保持一致,但如果无法形成主节点法定人数,则会牺牲可用性。 为确保更新被正确应用,它使用序列号和主项进行并发控制。
- PostgreSQL (联邦式): 使用两阶段提交,使其成为一个 CA(一致性 + 可用性)系统。 它不能很好地容忍网络分区。
Why Document-oriented DBMS for Big data
- 关系模型核心的规范化导致数据被分割成许多fine-grained(细粒度)的表(例如,一个联系人信息可能被分为 person、telephone、email 和 address 表)
- 面向文档的模型使用更Coarse-grained(粗粒度)的方法。 相同的联系人信息将被存储在一个单一的文档中,电话号码和电子邮件等细节则作为数组嵌套在该文档内。减少数据关联,避免了关系型数据库中复杂地关联关系
- 这种粗粒度的、自包含的文档结构在网络分区期间不易出现问题,因为数据访问和修改都局限在同一分区内。这使其更利于实现分区容错性
- 粗粒度数据方便数据拓展,可以轻松添加新的字段而避免对整个表进行修改支持数据的拓展和升级。
Sharding
分片是“水平地”对数据库进行分区。 这意味着数据库的行(或文档)被分割成子集,每个子集存储在不同的服务器上。 每个子集被称为一个分片 (shard)。
优点:
- 通过将计算负载分散到多个节点来提高性能。
- 使数据管理更容易,例如,在向集群添加新节点时。
- 允许数据库总大小超过任何单个节点的存储容量。
分片策略: 提到了两种常见的策略:
- 哈希分片 (Hash sharding): 根据键的哈希值将行均匀地分布到整个集群, 负载均衡
- 范围分片 (Range sharding): 将相似的行(例如,来自同一地理区域的社交媒体帖子)存储在同一个分片上。
Difference between Replication and Sharding
- 复制 (Replication): 在不同节点上存储同一行或文档的副本,以使数据库具有容错性。
- 分片 (Sharding): 将数据分割成不同“块”的操作。
Elasticsearch
Pros
- 全文搜索 (Full-text search): 其核心优势,继承自 Apache Lucene。
- 基于时间的数据 (Time-based data): 非常适合检索像计算机日志这样的时间序列数据。
- 非结构化数据 (Unstructured data): 适合存储没有严格、预定义模式的数据。
- 不经常更改的数据 (Infrequently changed data): 非常适合一次写入、很少(或从不)更改的数据。
Cons
- 关联数据 (连接): 它不适合存储需要连接的高度关系型数据,如客户和发票。 对此,关系型数据库管理系统是更好的选择。
- 事务: 它一次只支持单个文档的安全事务,不支持复杂、多文档、要么全成功要么全失败的事务
- 频繁的更新/删除: 当一个文档被“更新”或“删除”时,旧版本只是被标记为待删除,然后添加一个新版本。 这会导致索引文件快速增长,因此对于频繁变化的数据效率不高。
Core Concept
- Index (索引): 类似于关系型数据库管理系统中的数据库table。
- Documents (文档): 索引中的单个数据项,以 JSON 格式表示,类似于行。
- Data stream (数据流): 一组共享通用命名模式的索引,通常用于轮换基于时间的数据,如日志。
- Shard (分片): 索引的水平分区。
- Replicas (副本): 分片的拷贝。 两个副本意味着总共有三个拷贝:一个主分片和两个副本分片。
- Node (节点): ElasticSearch 软件的一个实例。
- Cluster (集群): 一组共同协作管理相同索引的节点。
- Mappings (映射): 定义 JSON 文档中字段及其类型和索引方式的模式
Cluster
- 节点角色: 集群中的每个节点都被分配一个或多个角色。 两个必需的角色是主节点 (master) 和数据节点 (data)。
- 主节点: 主节点协调集群的操作,如分片分配和索引创建。 只能有一个活动的主节点,尽管其他节点可以是“符合主节点资格的 (master-eligible)”。
- 数据节点: 不符合主节点资格的数据节点仅管理数据,不参与主节点选举。
- 主节点故障: 当一个主节点发生故障时,其他符合主节点资格的节点会举行选举以选出新的主节点。 剩余节点上的副本分片会被提升为主分片,以替换故障节点上的任何主分片。
Index Status
此页定义了 ElasticSearch 索引的三种健康状态颜色。
- 绿色 (Green): 所有主分片和副本分片都已成功分配到节点上。 集群完全健康且具有冗余。
- 黄色 (Yellow): 所有主分片都已分配,但某些副本分片无法分配(例如,节点不足)。 集群功能齐全,但缺乏所需的数据冗余级别。
- 红色 (Red): 至少有一个主分片未被分配。 集群丢失了数据,某些查询可能会失败。
Sharding
- 分片策略: 默认情况下,ElasticSearch 使用基于文档 ID 的哈希分片 (hash sharding) 来均匀分布文档。 但是,可以在创建文档时提供自定义的路由值 (routing value) 来实现范围分片 (range sharding)。
- 性能: 搜索时每个分片使用一个线程。
- 最佳分片大小: 存在一个权衡。较大的分片搜索起来较慢,但过多的分片会消耗更多资源。 一个经验法则是,目标是每个分片约有2亿个文档,或大小在10GB到50GB之间。
- 分片数量: 通常情况下,拥有较多的主分片比太少要好,因为主分片的数量决定了一个索引可以有效使用的最大节点数。
Index Lifecycle Management (ILM)
- ILM 用于随着索引老化自动对其进行管理,特别是对于像日志这样随时间大量增长的数据。
- 阶段: 索引生命周期策略通过一系列阶段来定义:热 (Hot)、温 (Warm)、冷 (Cold)、冻结 (Frozen) 和删除 (Delete)。
- 节点层: 处于不同阶段的索引可以被分配到具有不同性能特征的节点上(例如,用于
data_hot节点的快速 SSD,用于data_cold节点的较慢磁盘)。 - 滚动 (Rollover): 一种更简单的方法是设置一个索引或数据流,在达到特定大小或存在时间后进行“滚动”(即创建一个新索引)。
- 示例: 一个名为
nginx-*的数据流可以被配置为在10天后进入“温”状态,并在30天后被删除。 这意味着在任何给定时间,你将只存储最近30天的数据。
Query DSL
Multiple Criteria Search
AND (与) 条件搜索
这个查询使用
bool查询中的must子句来组合多个条件,它要求所有子查询都必须匹配,相当于逻辑上的 AND 。查询的目标是选择mark(分数) 大于等于80,并且name(姓名) 匹配 "john" 的所有学生JSONPOST /students/_search { "query": { "bool": { "must": [ { "range": { "mark": { "gte": 80 } } }, { "match": { "name": "john *" } } ] } } }OR (或) 条件搜索
这个查询使用
bool查询中的should子句,它要求至少一个子查询匹配即可,相当于逻辑上的 OR 。查询的目标是选择所有分数高于90分 或者 姓名为 "john" 的学生JSONPOST /students/_search { "query": { "bool": { "should": [ { "range": { "mark": { "gte": 90 } } }, { "match": { "name": "john *" } } ] } } }
Geographic Search
这个查询使用 filter 子句中的 geo_shape 过滤器来查找所有地理位置 (location 字段) 落在指定边界框 (envelope) 内的文档 。
POST /filebeat-8.7.1/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates" : [ [ 13.0, -53.0 ], [ 14.0, -52.0 ] ]
},
"relation": "within"
}
}
}
}
}
}Parent-child Relationship Search
这个查询使用 has_parent 子句来查找子文档 。它会选择所有 mark 大于80的 "student" 文档,并且这些文档的父文档 ("course" 类型) 必须满足 coursedescription 字段匹配 "Cloud Computing" 的条件 。
GET /search
{
"query": {
"bool": {
"must": [
{
"range": {
"mark": {
"gt": 80
}
}
},
{
"has_parent": {
"parent_type": "course",
"query": {
"match": {
"coursedescription": "Cloud Computing"
}
}
}
}
]
}
}
}SQL
Geographic Search
这个查询使用了filter子句来嵌入一个 Query DSL 地理形状过滤器,用以选择所有位于特定地理边界框内的文档 。这种方法结合了 SQL 的可读性和 Query DSL 的强大功能 。
POST /_sql?format=text
{
"query": "SELECT data.status, data.type FROM \"filebeat-8.7.1\"",
"filter": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [ [ 13.0, -53.0 ], [ 14.0, -52.0 ] ]
},
"relation": "within"
}
}
}
}Text Search
这个查询使用 MATCH 函数来查找 message 字段中包含 "Windows" 文本的文档 。
POST /_sql?format=txt
{
"query": "SELECT data.status, data.type FROM \"filebeat-8.7.1\" WHERE MATCH('message', 'Windows')"
}Keyword Search
这是一个在 keyword 类型字段上进行精确匹配的查询 。它使用了 LCASE 函数将字段值转换为小写,以实现不区分大小写的相等性比较 。
POST /_sql?format=txt
{
"query": "SELECT data.status FROM \"filebeat-8.7.1\" WHERE LCASE(data.type) = 'chatcompletions-request'"
}Time Search
ElasticSearch 提供了灵活的时间函数 。
查询两天前的观测数据 :
JSONPOST /_sql?format=txt { "query": "SELECT \"@timestamp\", data.status FROM \"filebeat-8.7.1\" WHERE \"@timestamp\" < TODAY() - INTERVAL '2' DAYS" }查询过去四个月内记录的观测数据,并按年份和状态分组 :
JSONPOST /_sql?format=txt { "query": "SELECT DATE_PART('year', \"@timestamp\") AS D, data.status FROM \"filebeat-8.7.1\" WHERE \"@timestamp\" > (TODAY() - INTERVAL '4' MONTH) GROUP BY D, data.status" }
Pagination
ElasticSearch SQL 通过返回一个 cursor (游标) 来实现分页,默认情况下一次返回1000行 。
第一页请求: 发出初始查询。响应中会包含一个
cursor字符串 。JSONPOST /_sql?format=json { "query": "SELECT HISTOGRAM(\"@timestamp\", INTERVAL 1 HOUR) AS H, COUNT(*) AS N FROM \"filebeat-8.7.1\" GROUP BY H" }后续页面请求: 要获取下一页结果,需要将上一次响应中收到的
cursor字符串包含在下一次请求中 。当返回的cursor字段为空时,表示所有结果都已检索完毕 。JSONPOST /_sql?format=json { "query": "...", "cursor": "t8jsAORGTACkUlu00z..." }
Aggregation
度量聚合 (Metric Aggregation): 使用标准的 SQL 聚合函数,如
COUNT(*)和SUM()。JSONPOST /_sql?format=txt { "query": "SELECT data.status AS STATUS, SUM(data.payload_size) AS SIZE FROM \"filebeat-8.7.1\" GROUP BY data.status" }桶聚合 (Bucket Aggregation): 桶聚合可以将文档分组到集合(“桶”)中,类似于直方图的条形 。以下查询使用
HISTOGRAM函数按年对文档进行分桶 。JSONPOST /_sql?format=txt { "query": "SELECT HISTOGRAM(CAST(date AS TIMESTAMP), INTERVAL 1 YEAR) AS D, COUNT(*) AS N FROM temperatures GROUP BY D" }
OLAP
ElasticSearch SQL 支持 PIVOT 子句,可以生成列联表,将某些行的值转换为列,以进行类似 OLAP 的分析 。
POST /_sql?format=txt
{
"query": "SELECT * FROM (SELECT rel_hum, stationid, air_temp FROM observations) PIVOT (AVG(air_temp) FOR rel_hum IN (65.0, 66.0, 67.0))"
}Exam questions
Many research domains are facing “big data” challenges. Big data is not just related to the size of the data sets. Explain.
回答 big data challenge 的特点有 V 即 velocity variety 和 veracity,并对每个 V 进行解释。Velocity:当面临高速度数据处理能力以应对高速数据接收需求,如实时 gps、传感器数据等。Variety:如数据存在结构化、半结构化、非结构化特性,且存在多数据的融合使用。Veracity:随着数据增多,容易产生噪声数据、缺失数据、离散数据,均影响分析,所以需要数据清洗或验证1。
What capabilities are currently offered or will be required for Cloud computing infrastructures such as the Melbourne Research Cloud to tackle these “big data” challenges? You may refer to the specific demands of particular research disciplines in your answer, e.g. life sciences, astrophysics, urban research etc.
结合 cloud computing 的五大特性,以及解决的问题进行讨论。举例:如天文数据量大,需要实时观测和高速数据传输和存储,甚至需要进行实时的数据分析。cloud computing 通过分布式数据存储及其 elasticity 解决存储和传输问题,MRC 的 Shibboleth 验证保证了数据存储和平台操作的安全性和合规,平台提供的容器化部署可以协助加速数据分析进度,缩短研究周期1。
A node belonging to a four-node CouchDB cluster with n=2 replicas and q=8 shards crashes. What happens to the documents stored on it?
25% of the documents are lost and cannot be retrieved.
All documents can still be retrieved.
The cluster becomes unstable and some documents may no longer be retrieved.
应该选 2。虽然这里是 couchDB,但和 elasticsearch 均属于 document oriented DBMS,是同一个 feature。系统由于存在一个 primary 和两份 replica,且 master node 会自动进行分配,使得 shard 的不同副本需要分布在不同节点,所以单个节点的 crash 不会导致任何一份数据无法获取2。
Three nodes belonging to a four-node CouchDB cluster with n=2 replicas and q=8 shards crash, what happens to the documents stored on it?
75% of the documents are lost and cannot be retrieved.
All documents can still be retrieved.
The cluster becomes unstable and some documents may no longer be retrieved.
应该选 3。任何一份 shard 会因为分布规则的限制存在于三个节点上,当系统有三个节点 crash 时,可能三份数据都不存在了,并且由于半数以上的节点 crash,整个系统会进入不稳定状态,无法对数据请求进行相应,也不存在数据的同步和备份2。
In the context of distributed databases, explain the concepts of Consistency and availability
Consistency: 每个 client 从所有 node 获得的响应相同。 Availability: 每个 client 都可以从 cluster 中任何 node 获得回应2。
Give an example of a database technology that supports Availability in the presence of a (network) partition.
可以直接用 elastic search 举例,其 shard 和 replica 的特性可以在部分节点掉线或 crash 的时候,通过副本保证所有数据的可用性3。
In the context of Elastic Search clusters what is the meaning of:
Replica number
一份数据被复制了几份副本Number of shards
一份数据被划分成了多少个部分3。